Your cart is empty
AI demand is growing faster than the infrastructure beneath it. Not just faster than chip production, faster than power delivery, faster than cooling capacity, faster than the pace at which new sites can be permitted and built. Inference is becoming “always on” across products and industries, and that shift is colliding with the physical reality of electricity, land, and timelines.
GPU availability is one pressure point. The bigger one is that AI-ready facilities increasingly look like power projects: long lead times, constrained grid connections, and expensive upgrades. That’s why a new category is emerging: distributed AI infrastructure, systems that scale by using what already exists, not only by building anew. Exeton sits in that movement, focused on scaling AI inference infrastructure by tapping existing infrastructure and underutilized power capacity, rather than waiting years for every incremental megawatt to come online in a traditional hyperscale data center.
The provocative idea is simple: if AI compute is becoming a utility, the next expansion won’t come from one place. It will come from everywhere.
Centralized data centers are still the backbone of modern computing. They’re efficient, secure, and operationally mature. But AI changes the scaling equation.
Even well-run projects face permitting, transformer procurement, switchgear lead times, and construction constraints. Inference demand, by contrast, can spike with a single product launch or model upgrade.
For AI, the limiting resource is often the ability to deliver megawatts reliably, not the ability to rent racks. Grid interconnection queues, substation capacity, and regional generation constraints can stall growth even when capital is available.
Higher power density means more complex cooling, stricter operational envelopes, and more expensive infrastructure per unit of compute. Add land scarcity in high-demand regions, and “just build another campus” becomes less straightforward.
None of this makes hyperscale irrelevant. It just suggests that centralized models alone may not be able to scale quickly enough, especially for inference workloads that are latency-sensitive and widely distributed.
The next layer looks less like a monolith and more like a network.
Distributed AI infrastructure is an architecture where many smaller compute nodes, spread across different locations, are coordinated through software to behave like a single platform. Think of it as a distributed GPU network with:
A control plane for orchestration and scheduling
Policy and security controls for workload isolation
Telemetry to route jobs based on performance, cost, and power conditions
This approach is especially relevant for edge AI compute and edge inference computing, where response time and locality matter. It also helps address a practical constraint: smaller deployments can often be stood up faster than large, centralized builds.
Training thrives on tightly coupled clusters and specialized interconnect. Inference, by comparison, is often more parallel and elastic. That makes it a strong candidate for a decentralized AI compute layer—particularly when the goal is to add capacity quickly and place it closer to users.
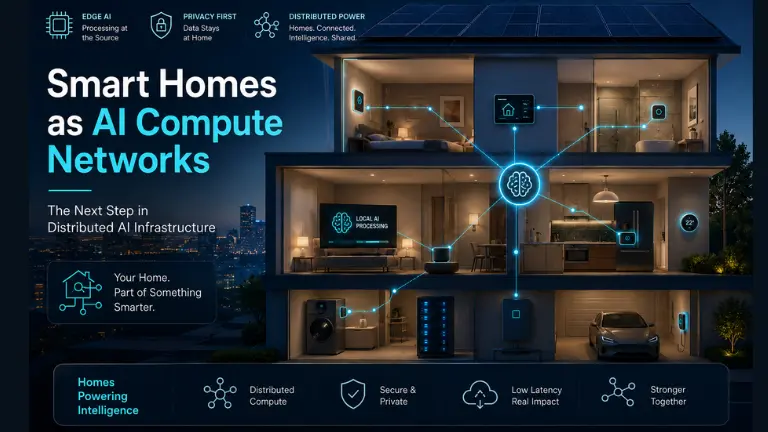
“Smart homes and AI” can sound like a consumer trend. The infrastructure angle is more interesting: buildings are quietly accumulating the components of a compute substrate.
Modern homes and buildings increasingly have:
Residential and commercial electrical systems are already distributed—by definition. Many sites also have unused headroom at certain times of day, seasons, or occupancy patterns. That underutilization is an opportunity if managed safely.
Home batteries and building storage turn energy into something schedulable. Solar adds local generation. Together, they create flexibility that can support bursty inference workloads or shift compute to off-peak periods.
Fiber isn’t universal, but broadband performance continues to improve, especially in newer developments. Not every workload needs ultra-low latency; many inference jobs just need reliable upstream bandwidth and smart routing.
A large share of electrical infrastructure is built for peaks that don’t occur continuously. Unlocking that “slack”, across time, geography, and building types, could add meaningful compute capacity without waiting for greenfield data center expansions. This is one of the core economic arguments for AI infrastructure scaling through distribution.
To become real infrastructure, distributed compute has to feel dependable: predictable performance, clear security boundaries, and orchestration that hides complexity from customers.
At a high level:
A scheduler assigns inference requests to nodes based on latency targets, node health, bandwidth, and energy constraints. When conditions change, congestion, outages, price signals, the system reallocates.
The likely end state is hybrid AI infrastructure:
Best for large batch inference, centralized services, and heavy training.
Best for latency-sensitive, regional, and burst workloads, especially where capacity can be deployed quickly.
AI assistants that benefit from regional routing and lower latency
Autonomous and robotic systems that need fast perception loops
Medical imaging support where some inference can run near clinics for speed and governance
Industrial monitoring with real-time alerts and local decision-making
Not everything belongs in a home. But many inference workloads don’t need a hyperscale campus either.
A distributed GPU network is not automatically a reliable platform. Several hard problems remain:
Workloads running across many sites require strong isolation, secure provisioning, and verification that nodes are uncompromised.
Heterogeneous hardware and network conditions create operational complexity. Practical standards for management, telemetry, and packaging will matter.
If compute is energy-aware, it must coordinate responsibly, supporting the grid rather than creating new peaks.
Hosting, maintenance, and payout models must be predictable enough to scale, especially if nodes are deployed across third-party sites.
The infrastructure world tends to cycle between centralization and decentralization. The more realistic outcome is layered: centralized cores plus distributed edges.
Exeton’s perspective is that the future of AI data centers isn’t a single “next big campus.” It’s a networked system where distributed AI infrastructure complements hyperscale facilities, especially for AI inference infrastructure. By building on existing infrastructure and capturing underutilized power capacity, Exeton aims to deploy inference compute faster and cheaper than traditional approaches, while keeping reliability and coordination at the center of the design.
Inference demand will keep expanding across products, cities, and industries, and the fastest path to capacity will be hybrid, not purely centralized.
AI is becoming a physical-economics problem: watts, cooling, site readiness, and time. As inference spreads into everyday workflows, compute won’t live only in faraway campuses. It will move outward into a distributed ecosystem that looks a lot like the built environment itself.
Smart homes and buildings won’t replace hyperscale data centers. But they could become part of the next compute layer, an edge AI compute fabric that is energy-aware, geographically distributed, and orchestrated as a single platform. If the last decade was about centralizing compute in the cloud, the next may be about distributing it intelligently.
That’s the world Exeton is preparing for: a future where AI scales because infrastructure and energy systems evolve together, and where the “data center” becomes less a place and more a network.
Because power availability, cooling requirements, land constraints, and long build times are limiting expansion speed.
It is a system where AI compute is spread across many smaller nodes instead of being concentrated in large data centers.
Yes, in the form of lightweight inference tasks when excess energy and idle hardware capacity are available.
It is AI processing that happens closer to the user or data source instead of relying on centralized cloud infrastructure.
Exeton is focused on building distributed AI infrastructure that uses existing energy and infrastructure to scale inference compute more efficiently.